Data acquisition pipelines¶
Data acquisition pipelines perform all processes related to data normalization, quality, and storage.
A pipeline comprises one or more nodes that are connected with each other to define execution dependencies.
Pipeline templates¶
A pipeline template defines the structure and the workflow of a pipeline. A pipeline template is built with nodes and edges. Each node represents a component that can be executed as long as the preconditions required for its execution are met (inputs parameters, access to resources, runtime environment).
Managing pipeline execution as a sequence of independent components makes it easy to create new pipelines from the library of components available in the TranzAI platform. Adding new components is also a simple process since the design and testing of these components are based on coding patterns that ensure their integration into the TranzAI SDK.

Pipeline for data consolidation¶
To create a data acquisition pipeline, select the pipeline template that matches the sequence of operations you want to perform, followed by the data source from which you want to consolidate data for your project.
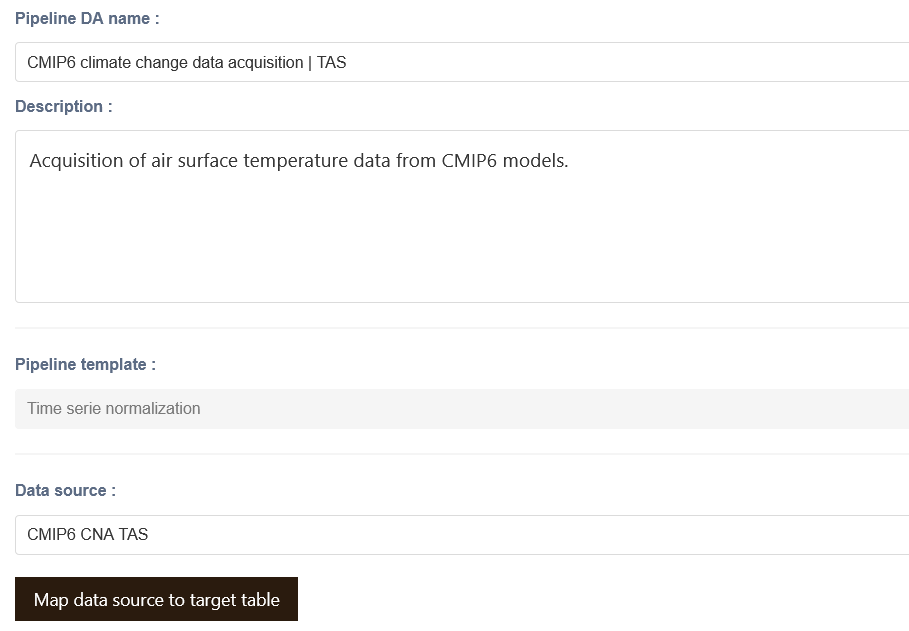
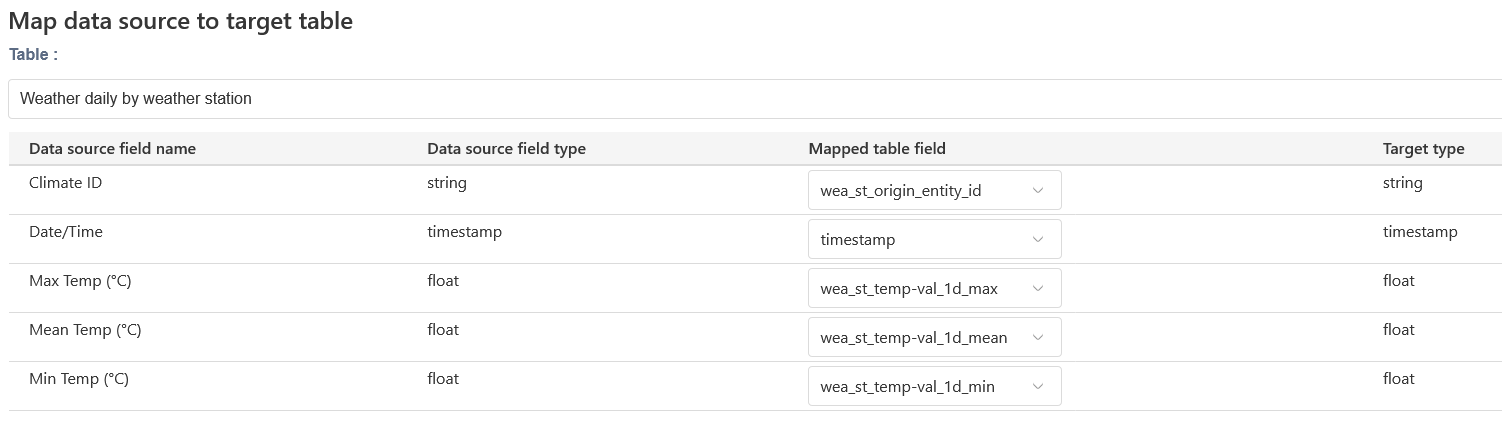
Data source mapping¶
A data source instance is always mapped to a target table in the feature store, except for loading raw data as-is to perform quick exploration and analysis of a dataset to see if it can respond to your research needs.
Note
If your data source instance has been configured with instantiation parameters, you will be asked to select the parameters that correspond to your data set to automatically complete the mapping and storage of your data under the appropriate partition in your feature store.
Time series consolidation¶
Time series are consolidated in the TranzAI Parquet feature store and can be analyzed through time series feature tables. Raw data can be directly analyzed and integrated into analytical dashboards.
Note
If you plan to use this data in feature engineering processes that may require several transformation and enrichment steps, we strongly recommend performing an extra step of data normalization to benefit from the data lineage and explainable AI capabilities of the TranzAI platform.
Entity acquisition¶
Entities are consolidated in the TranzAI spatial backend that provides specific features dedicated to managing spatial data types (points, lines, and polygons), coordinate systems and spatial indexing. You can use the TranzAI platform's pre-built entity pipelines to consolidate and index your entities with a user-friendly no-code GUI.
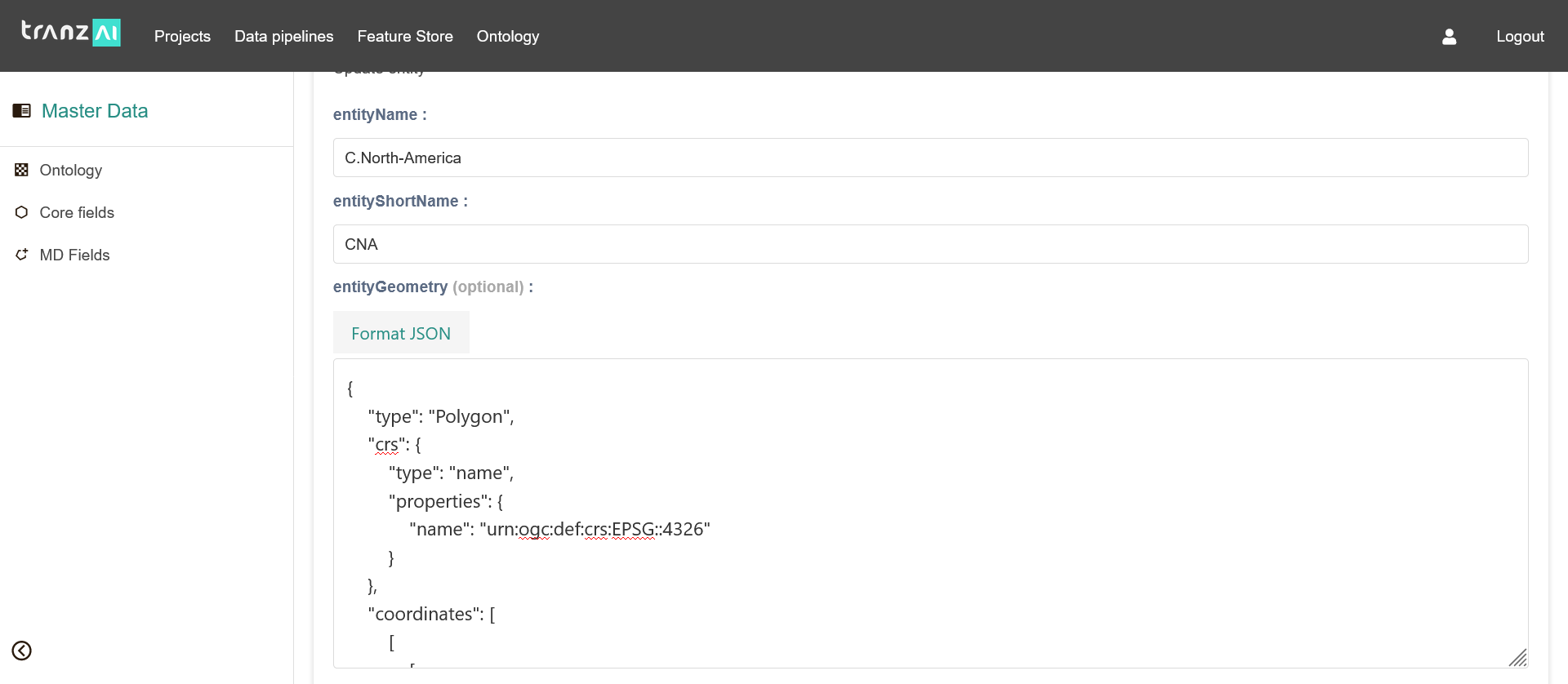
If your spatial entities are already stored in a repository or available through an API, the management of spatial data types is done at the data source level to map this data with the types that are mostly used in the TranzAI platform (GeoJSON, WKT).
Optical satellite image acquisition¶
Satellite images for Earth observation are acquired and analyzed in dedicated worflows available in TranzAI EO.
Pipeline instances¶
Each time you run a pipeline, the TranzAI platform saves a pipeline instance that stores all runtime parameters. In the event of a problem during execution, you can always go back to a pipeline instance to relaunch a pipeline with the initial configuration or to apply a correction to this instance if necessary.
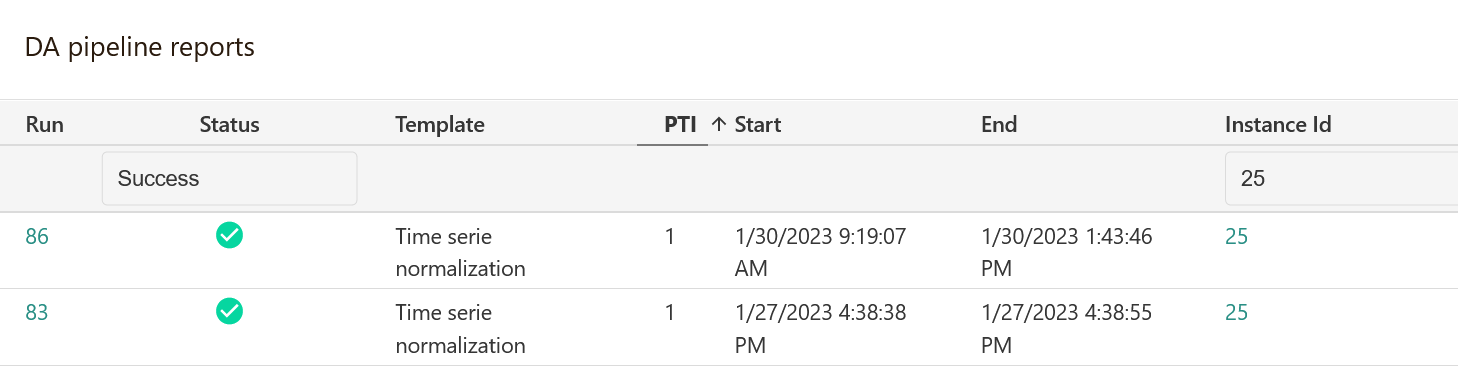
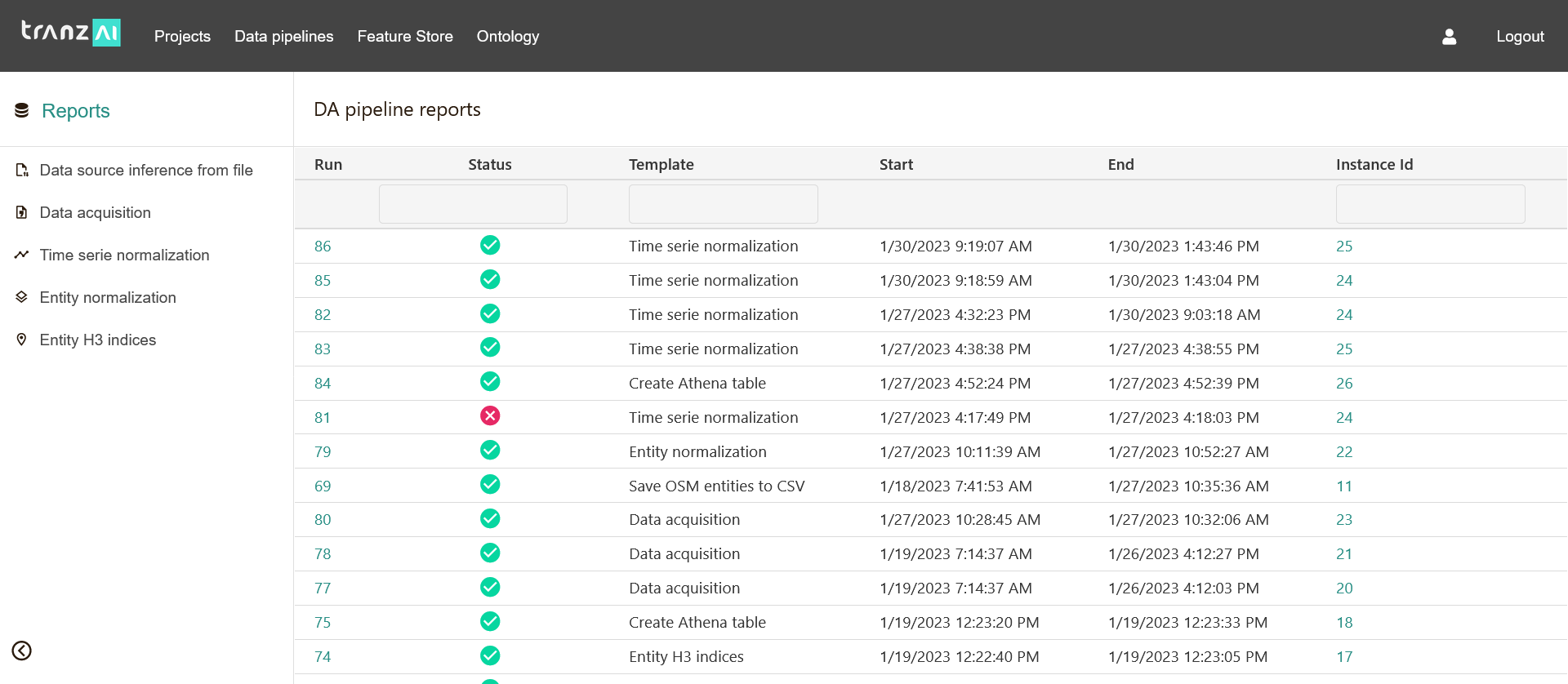
Pipeline reports¶
Pipeline reports give you a clear and precise interface to track all your pipelines. They are automatically linked to the main entities associated with a given pipeline (data source, dataset, feature table...) to facilitate their analysis as part of your data science project.