Feature management¶
Feature lineage¶
The origin of a feature is either a data source field that has been normalized in a data acquisition pipeline and stored as such in the feature store, or a raw field of a data source instance to which is applied an initial transformation before being stored in the feature store.
In both cases, the data lineage is provided by the table that was used to extract this feature at feature extraction pipeline level. When a feature itself becomes a parameter of a higher-level feature extraction process, subsequent features keep track of the origin of the data source and any transformations previously applied to the raw data.
Feature design¶
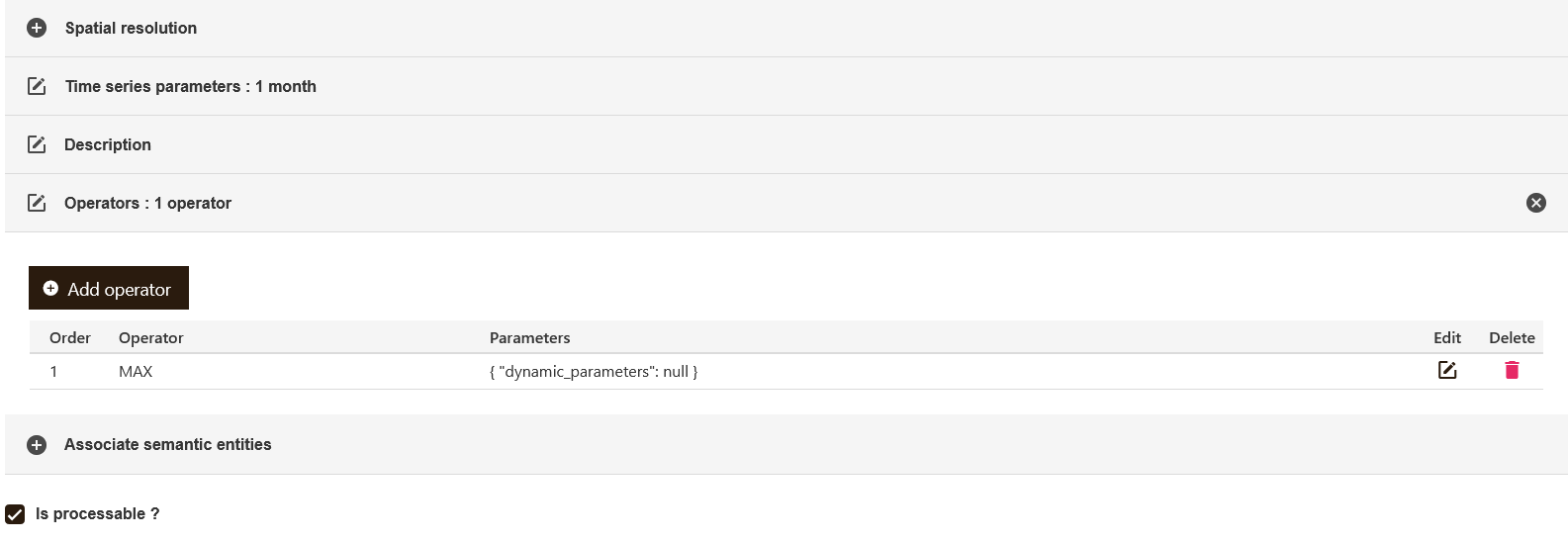
The TranzAI GUI provides a feature design component to help better define and classify features:
-
Is it a time serie, a spatial feature or an entity feature?
-
What is the origin of the data?
-
Does is related to a specific entity in the ontology?
-
What type of transformation is applied to this data?
-
What is its resolution?
This information clarifies the administration of your feature store and will also help you design your feature extraction pipelines and decide how to efficiently store your features to facilitate their use both at model training level and at scoring level.
Feature catalog¶
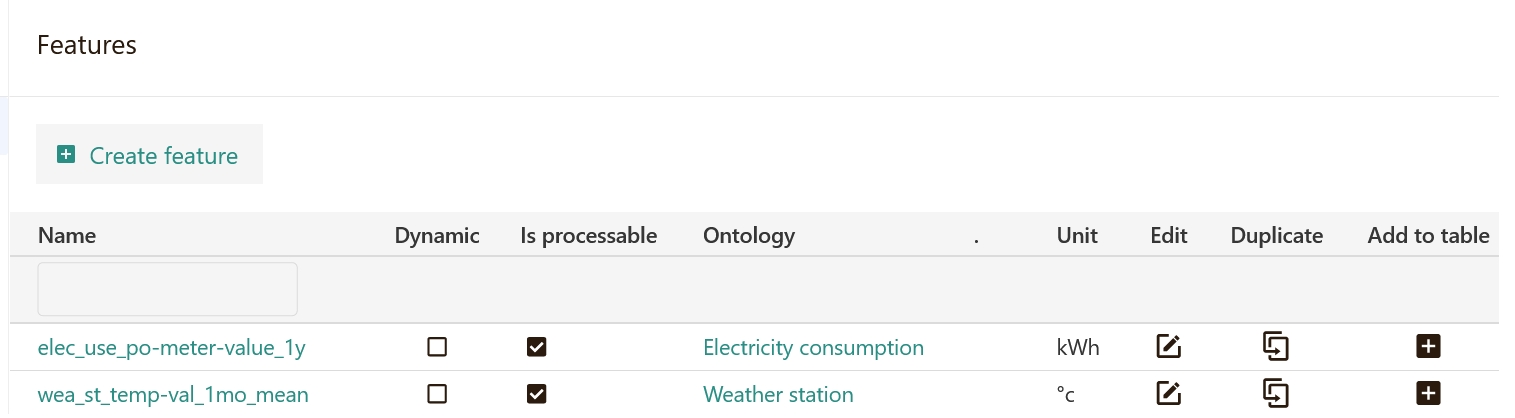
Each new feature is added to the feature catalog. Step by step, each member of the data science team is contributing to the development of a central repository that document all feature-related information and provide a comprehensive list of potential features that can be used for model design and training.
Once a feature has been documented in the catalog, it can be easily reused in other projects or models. This can save time and effort by avoiding the need to recreate the same feature from scratch for each new project.
Feature use¶
Once a feature is designed and associated to a feature table it becomes available for feature selection and model training processes.
The TranzAI platform automatically register how features are used at model training level.