Feature extraction pipelines¶
FE pipelines are essential building blocks in the management of your feature engineering processes. FE pipelines contain all the data enrichment and preprocessing steps that are required to transform raw data into measurable property or characteristic that can used as input for machine learning algorithms.
Feature extraction pipeline management¶
All FE pipeline in the TranzAI platform are tigtly tied to feature tables defined in the feature store. They inherit all their properties (spatial resolution and temporal resolution) as well as all the properties of each field associated to a feature table (type, constraint, format).
Feature extraction pipeline workflow¶
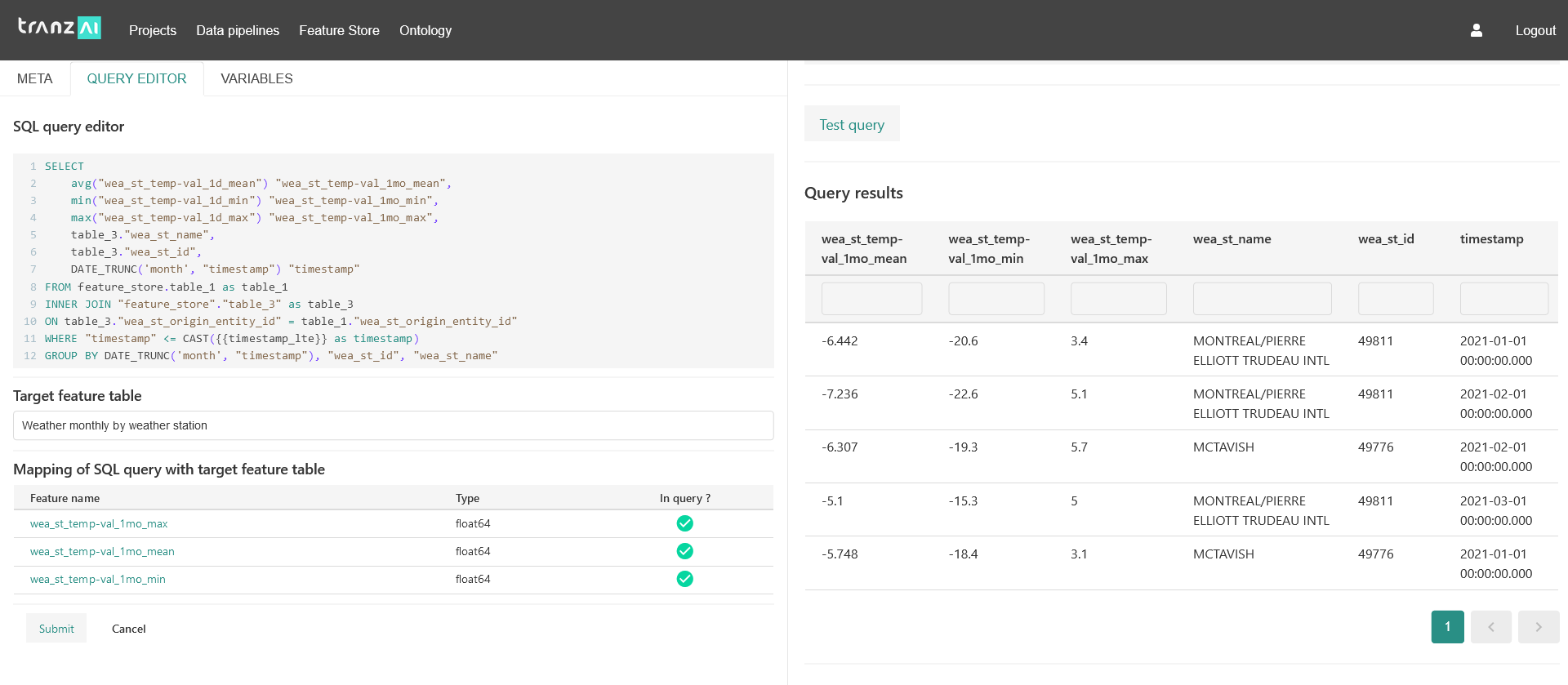
Create pipeline / SQL based feature extraction¶
SQL is the most efficient language to define and execute feature extraction processes on Parquet data stored in TranzAI feature store. You can write your code directly in the IDE provided in the feature pipeline interface.
Create pipeline / Python-based feature extraction¶
Some transformations and analyzes cannot be performed with SQL and rely on specialized Python libraries. This is the case for analysis and advanced transformations of spatial data. In this case, you can benefit from access to specialized python spatial libraries built into TranzAI.
Feature extraction pipeline scheduling¶
Time-dependent feature extraction processes can benefit from automating feature extraction. Depending on how often your data is updated and the transformations applied to time-related features, you can define features that contain time-related variables that can be automatically instantiated each time a scheduled pipeline runs.
Feature extraction pipeline reports¶
Like DA pipelines, each instance of a feature extraction pipeline is saved with the parameters used at runtime.