Feature tables¶
The feature store is structured with tables. Storing features in tables present several advantages for large-scale feature store management:
- Tables can store large amounts of data since they represent the Parquet data consolidated in the feature store.
- Tables can be easily queried using SQL, allowing data scientists and machine learning engineers to retrieve at large scale the data they need to train models, run experiments and consolidate the feature store.
- Tables fields are directly linked to the master data.
- Tables make it easy to implement data models optimized for feature store management, ensuring that data is meaningfully organized, easily accessible, and scalable to meet the demands of data-intensive applications.
- Tables are a core component of feature extraction pipeline design. The attributes of the tables, and in particular the temporal and spatial granularity, make it possible to design coherent processes for enriching the data.
Feature table management¶
Create table¶
You can create or edit a table from the feature store homepage. Creating a feature table is done in two steps. You first define the purpose of the table and its generic characteristics. You can then work on designing the table schema itself.
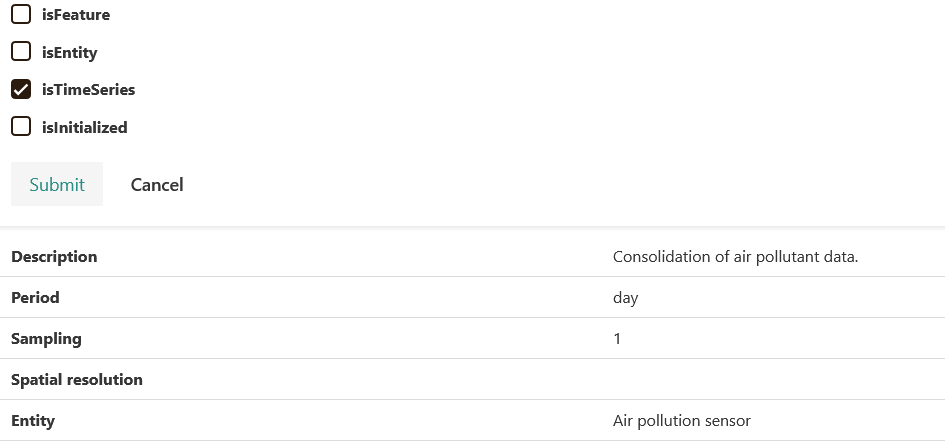
Add field to table¶
You can add a field to a table directly from the table interface by selecting an existing feature.
You can also add a feature to a table from the feature page.
The table metadata is automatically created from information available at the master data level.
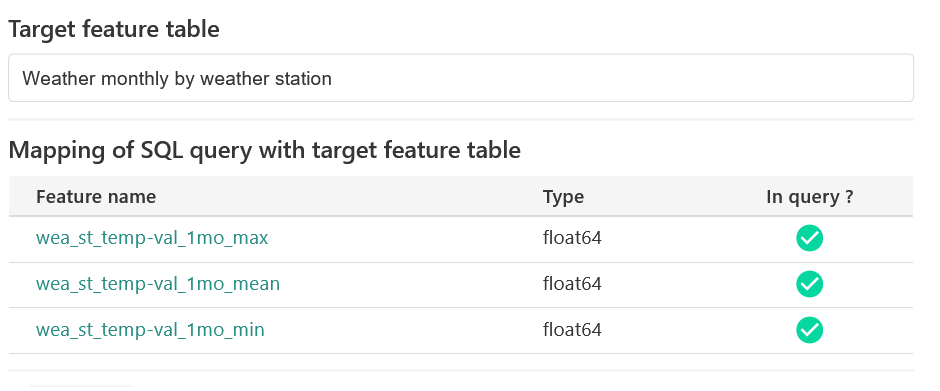
Deploy table to feature store¶
When designing a table with the GUI of the TranzAI platform, you automatically create the metadata that contains all the information related to this table. Once the design phase is complete, you must physically deploy this table to the feature store using the "deploy" icon available at the table page level.
Note
Feature tables can be used as target tables for FE pipelines, data source instance mapping or query design only after they have been physically deployed.
Use a feature table as a target table for FE pipelines¶
Feature extraction pipelines always use a feature table to store the results of the calculation performed on data stored in the feature store. Most of the time, you can directly execute operations from feature tables with SQL. When transformations require specific operators only available in Python, data is taken from tables and processed with the appropriate libraries before being saved to the feature store.