Training data sets¶
The Training Data Set is a central entity for model documentation and reproducibility of R&D steps undertaken for any model trained and tested within the TranzAI platform.
TD set are key enablers for model design and model training. TD sets helps you leverage all the work done at data acquisition and feature engineering level to iteratively build, train and test machine learning models.
Note
Each model designed and trained with the TranzAI platform is associated with a training data set that consolidates all data transformations and data lineage information.
Exploratory Data Analysis (EDA) on TD sets¶
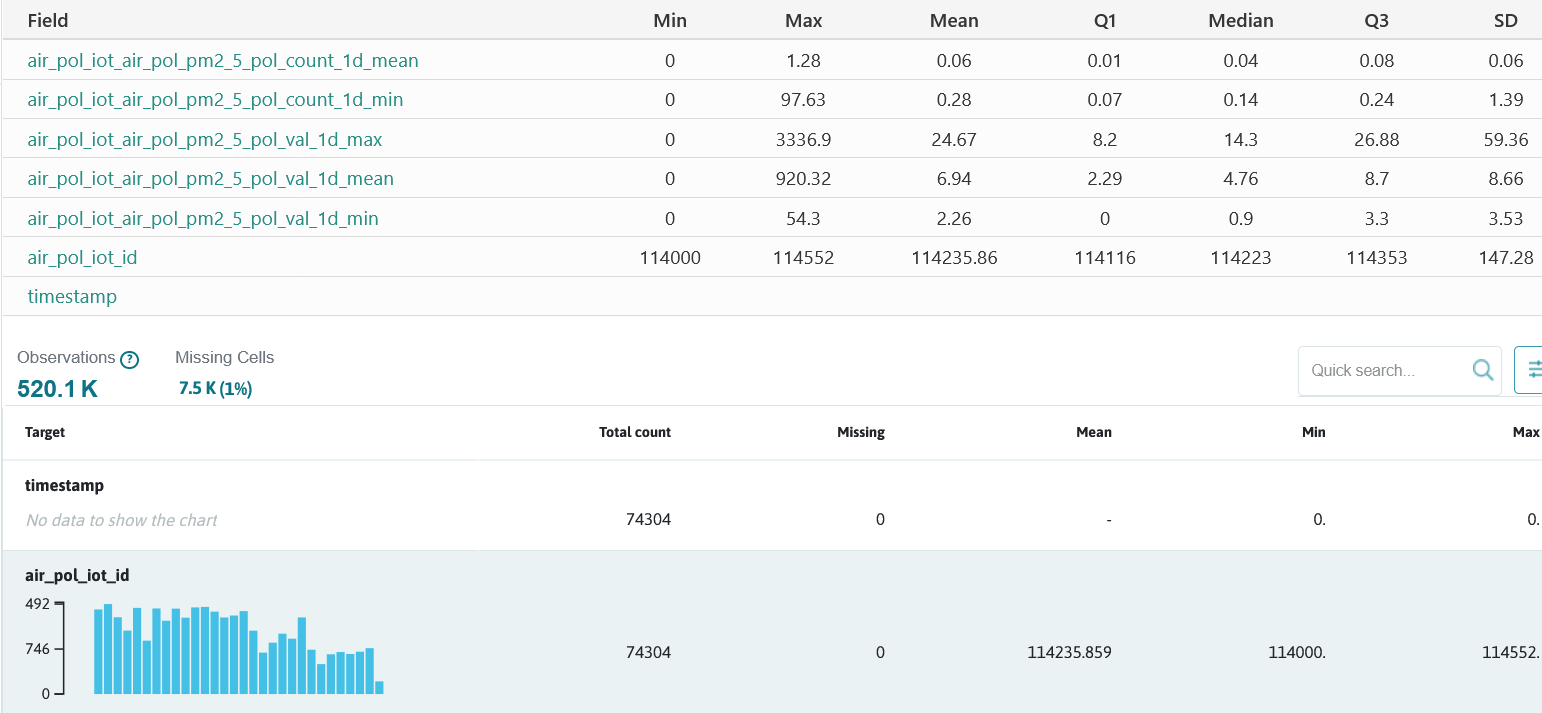
The EDA performed on your training data set is a critical step in your machine learning workflow as it will provide a better understanding of the data used for designing and training your models.
The TranzAI platform provides a default EDA component that is executed for each new TD set created. Specialized EDA dashboards can be created through the analytics GUI to provide a more accurate understanding of the data available for training.
Exploratory Spatial Data Analysis (ESDA) on TD sets¶
Spatiotemporal data being complex data by nature, it is highly recommended to use the data visualization and analytical tools of the TranzAI platform to create EDA dashboards that combines time serie and spatial visualization for a better assessment of the quality and characteristics of the available data.
TD set creation workflow¶
Target definition¶
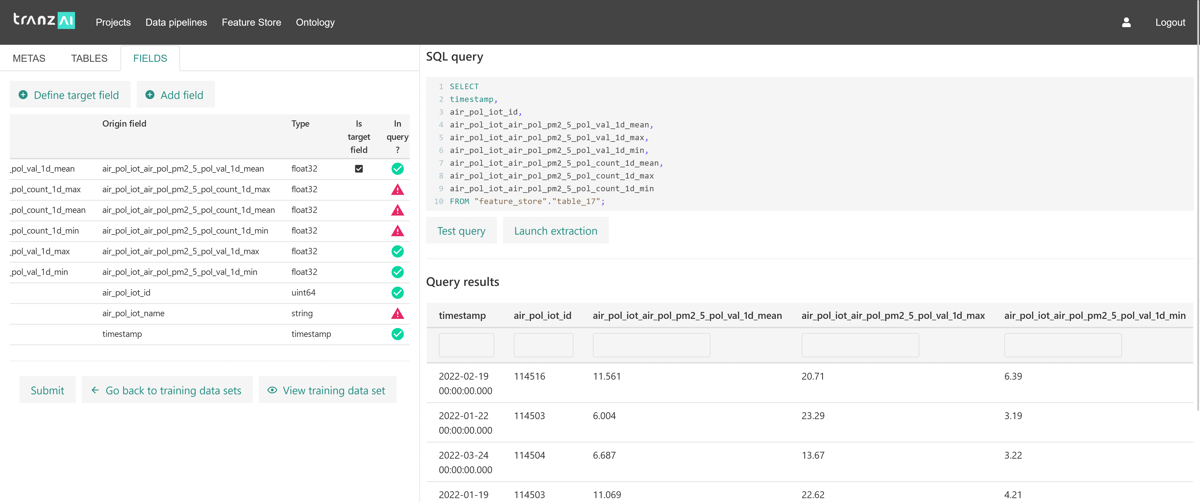
The target feature should be the first variable that you define in your training dataset. If you have defined your features through the TranzAI feature store GUI, the selection of the target feature simply requires to select the field used as the response variable in one of the table that you associate to your TD set.
Feature extraction¶
The extraction of a TD set is based on a custom query that is run against the feature store. To secure data lineage at the model level, TranzAI's GUI provides an SQL query wizard that verifies that the query contains all features associated with the TD set.
Pipeline execution¶
Running a TD pipeline simply requires executing the query once it matches the definition of the TD set.
Note
Once a TD set is extracted, it cannot be modified because its definition and statistical characteristics are an intrinsic part of all training workflows that will use this TD set.